Java: How to Become More Productive with Hazelcast in Less Than 5 Minutes
What if you want to use a Hazelcast In-Memory Data Grid (IMDG) to speed up your database applications, but you have hundreds of tables to handle? Manually coding all Java POJOs and serialization support would entail weeks of work and when done, maintaining that domain model by hand would soon turn into a nightmare. Read this article and learn how to save time and do it in 5 minutes.Now there is a graceful way to manage these sorts of requirements. The Hazelcast Auto DB Integration Tool allows connection to an existing database which can generate all these boilerplate classes automatically. We get true POJOs, serialization support, configuration, MapStore/MapLoad, ingest and more without having to write a single line of manual code. As a bonus, we get Java Stream support for Hazelcast distributed maps.
Using the Tool
Let us try an example. As in many of my articles, I will be using the Sakila open-source example database. It can be downloaded as a file or as a Docker instance. Sakila contains 16 tables and a total of 90 columns in those tables. It also includes seven views with additional columns.To start, we use the Hazelcast Auto DB Integration Initializer and a trial license key.
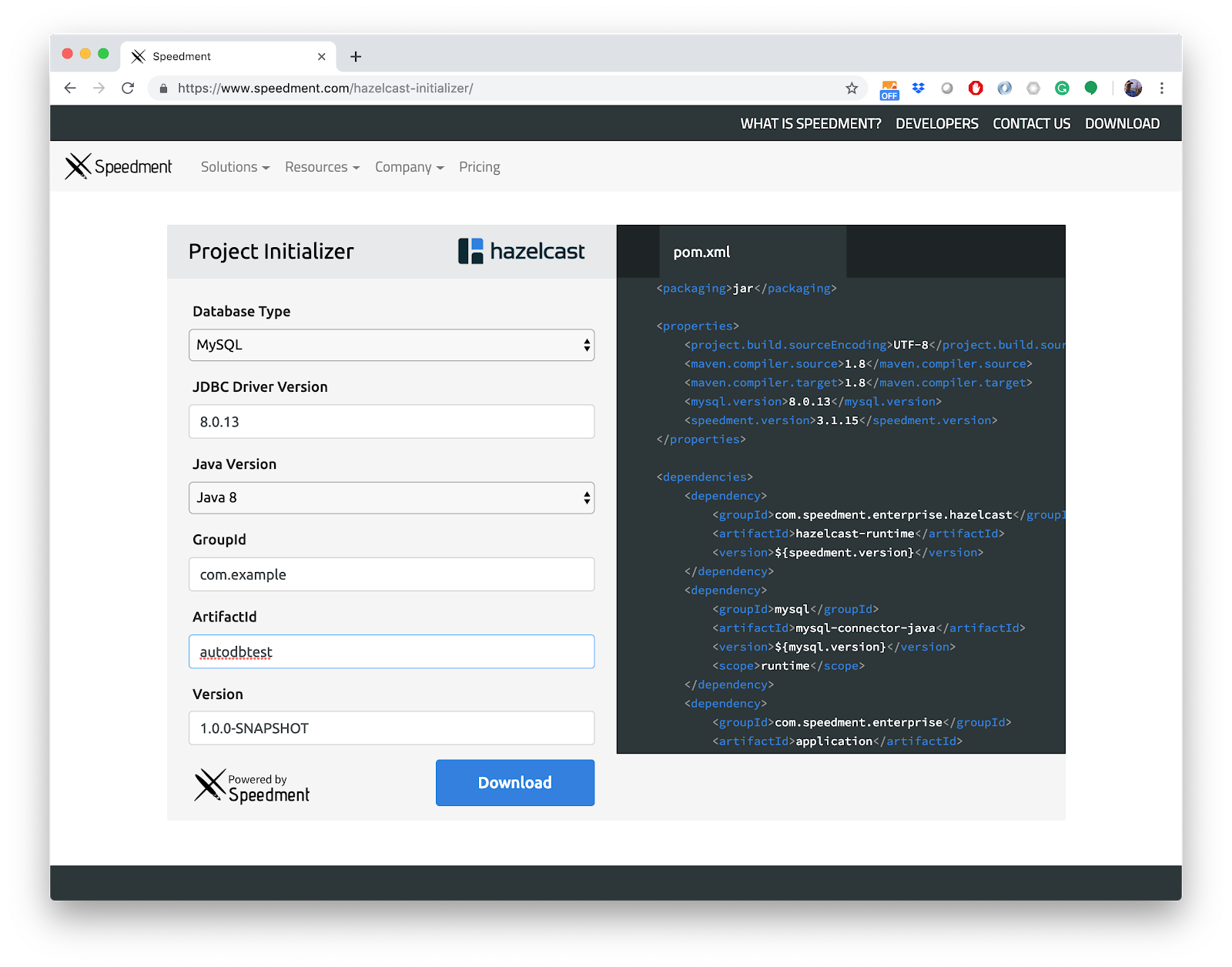
Fill in the values as shown above and press “Download” and your project is saved to your computer. Then, follow the instructions on the next page explaining how to unzip, start the tool and get the trial license.
Next, we connect to the database:

The tool now analyses the schema metadata and then visualizes the database schema in another window:

Just press the “Generate” button and the complete Hazelcast domain model will be generated automatically within 2 or 3 seconds.

Now, we are almost ready to write our Hazelcast IMDG application. We need to create a Hazelcast IMDG to store the actual data in first.
Architecture
This is how the architecture looks like where the Application talks to the Hazelcast IMDG which, in turn, gets its data from the underlying Database:
The code generated by the tool need only be present in the Application and not in the Hazelcast IMDG.
Creating a Hazelcast IMDG
Creating a Hazelcast IMDG is easy. Add the following dependency to your pom.xml file:<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>3.11</version>
</dependency>
Then, copy the following class to your project:
public class Server {
public static void main(String... args) throws InterruptedException {
final HazelcastInstance instance = Hazelcast.newHazelcastInstance();
while (true) {
Thread.sleep(1000);
}
}
}
Run this main method three times to create three Hazelcast nodes in a cluster. More recent versions of IDEA requires “Allow parallel run” to be enabled in the Run/Debug Configurations. If you only run it once, that is ok too. The example below will still work even though we would just have one node in our cluster.
Running the main method tree times will produce something like this:
Members {size:3, ver:3} [
Member [172.16.9.72]:5701 - d80bfa53-61d3-4581-afd5-8df36aec5bc0
Member [172.16.9.72]:5702 - ee312d87-abe6-4ba8-9525-c4c83d6d99b7
Member [172.16.9.72]:5703 - 71105c36-1de8-48d8-80eb-7941cc6948b4 this
]
Nice! Our three-node-cluster is up and running!Data Ingest
Before we can run any business logic, we need to ingest data from our database into the newly created Hazelcast IMDG. Luckily, the tool does this for us too. Locate the generated class namedSakilaIngest and run it with the database password as the first command line parameter or modify the code so it knows about the password. This is what the generated class looks like.public final class SakilaIngest {
public static void main(final String... argv) {
if (argv.length == 0) {
System.out.println("Usage: " + SakilaIngest.class.getSimpleName() + " database_password");
} else {
try (Speedment app = new SakilaApplicationBuilder()
.withPassword(argv[0]) // Get the password from the first command line parameter
.withBundle(HazelcastBundle.class)
.build()) {
IngestUtil.ingest(app).join();
}
}
}
}
When run, the following output is shown (shortened for brevity):...
Completed 599 row(s) ingest of data for Hazelcast Map sakila.sakila.customer_list
Completed 2 row(s) ingest of data for Hazelcast Map sakila.sakila.sales_by_store
Completed 16,049 row(s) ingest of data for Hazelcast Map sakila.sakila.payment
Completed 16,044 row(s) ingest of data for Hazelcast Map sakila.sakila.rental
Completed 200 row(s) ingest of data for Hazelcast Map sakila.sakila.actor_info
We now have all data from the database in the Hazelcast IMDG. Nice!
Hello World
Now that our grid is live and we have ingested data, we have access to populated Hazelcast maps. Here is a program that prints all films of length greater than one hour to the console using theMap interface: public static void main(final String... argv) {
try (Speedment app = new SakilaApplicationBuilder()
.withPassword("your-db-password-goes-here")
.withBundle(HazelcastBundle.class)
.build()) {
HazelcastInstance hazelcast = app.getOrThrow(HazelcastInstanceComponent.class).get();
IMap<Integer, Film> filmMap = hazelcast.getMap("sakila.sakila.film");
filmMap.forEach((k, v) -> {
if (v.getLength().orElse(0) > 60) {
System.out.println(v);
}
});
}
}
The film length is an optional variable (i.e., nullable in the database) so it gets automatically mapped to an
OptionalLong. It is possible to set this behavior to “legacy POJO” that returns null if that is desirable in the project at hand.There is also an additional feature with the tool: We get Java Stream support! So, we could write the same functionality like this:
public static void main(final String... argv) {
try (Speedment app = new SakilaApplicationBuilder()
.withPassword("your-db-password-goes-here")
.withBundle(HazelcastBundle.class)
.build()) {
FilmManager films = app.getOrThrow(FilmManager.class);
films.stream()
.filter(Film.LENGTH.greaterThan(60))
.forEach(System.out::println);
}
Under the Hood
The tool generates POJOs that implements Hazelcast’s “Portable” serialization support. This means that data in the grid is accessible from applications written in many languages like Java, Go, C#, JavaScript, etc.The tool generates the following Hazelcast classes:
POJO
One for each table/view that implements the Portable interface.Serialization Factory
One for each schema. This is needed to efficiently create Portable POJOs when de-serializing data from the IMDG in the client.MapStore/MapLoad
One for each table/view. These classes can be used by the IMDG to load data directly from a database.Class Definition
One for each table/view. These classes are used for configuration.Index utility method
One per project. This can be used to improve the indexing of the IMDG based on the database indexing.Config support
One per project. Creates automatic configuration of serialization factories, class definitions, and some performance setting.Ingest support
One per project. Template for ingesting data from the database into the Hazelcast IMDG.The tool also contains other features such as support for Hazelcast Cloud and Java Stream support.
A particularly appealing property is that the domain model (e.g., POJOs and serializers) does not need to be on the classpath of the servers. They only need to be on the classpath on the client side. This dramatically simplifies the setup and management of the grid. For example, if you need more nodes, add a new generic grid node and it will join the cluster and start participating directly.
Hazelcast Cloud
Connections to Hazelcast Cloud instances can easily be configured using the application builder as shown in this example:Speedment hazelcastApp = new SakilaApplicationBuilder()
.withPassword(“<db-password>")
.withBundle(HazelcastBundle.class)
.withComponent(HazelcastCloudConfig.class,
() -> HazelcastCloudConfig.create(
"<name of cluster>",
"<cluster password>",
"<discovery token>"
)
)
.build();
Savings
I estimate that the tool saved me several hours (if not days) of boilerplate coding just for the smaller example Sakila database. In an enterprise-grade project with hundreds of tables, the tool would save a massive amount of time, both in terms of development and maintenance.Now that you have learned how to create code for your first exemplary project and have set up all the necessary tools, I am convinced that you could generate code for any Hazelcast database project in under 5 minutes.
Resources
Sakila: https://dev.mysql.com/doc/index-other.html or https://hub.docker.com/r/restsql/mysql-sakilaInitializer: https://www.speedment.com/hazelcast-initializer/
Manual: https://speedment.github.io/speedment-doc/hazelcast.html
About
Per Minborg
Per Minborg is a Palo Alto based developer and architect, currently serving as CTO at Speedment, Inc. He is a regular speaker at various conferences e.g. JavaOne, DevNexus, Jdays, JUGs and Meetups. Per has 15+ US patent applications and invention disclosures. He is a JavaOne alumni and co-author of the publication “Modern Java”.