Here is a look at how you can write a full stack database web application without using SQL, HQL, PHP, ASP, HTML, CSS or Javascript and instead relying purely on Java using Vaadin’s UI layer and Speedment Stream ORM.

In this article, we will demonstrate how fast and easy this can be done by leveraging two Java frameworks; Vaadin and Speedment. Because they both use Java Streams, it easy to connect them together. This means we will end up with a short, concise and type-safe application.
The full application code is available at GitHub and you can clone this repository if you want to run the application in your own environment. You will also need trial licenses from both Vaadin and Speedment to use the features used in this article. These are available for free.
The intended end result is a web application where it is possible to analyze gender balance and salary distribution among different departments. The result is displayed graphically, using pure standard Vaadin Charts Java components as depicted in the video below:
Setting Up the Data Model
We are using Speedment Stream ORM to access the database. It is easy to set up any project using the Speedment initializer. Speedment can generate Java classes directly from the database’s schema data. After generation, we can create our Speedment instance like this:Speedment speedment = new EmployeesApplicationBuilder()
.withUsername("...") // Username need to match database
.withPassword("...") // Password need to match database
.build();
Create a Dropdown for Departments
In our web application, we want to have a drop-down list of all departments. It is easy to retrieve the departments from the database as can be seen in this method:public Stream<Departments> departments() {
DepartmentsManager depts = speedment.getOrThrow(DepartmentsManager.class);
return depts.stream();
}
Joining Departments and Employees Together
Now we are going to create a join relation betweenDepartments and Employees. In the database, there is a many-to-many relation table that connects these tables together named DeptEmpl. First, we create a custom tuple class that will hold our three entries from the joined tables:
public final class DeptEmplEmployeesSalaries {
private final DeptEmp deptEmp;
private final Employees employees;
private final Salaries salaries;
public DeptEmplEmployeesSalaries(
DeptEmp deptEmp,
Employees employees,
Salaries salaries
) {
this.deptEmp = requireNonNull(deptEmp);
this.employees = requireNonNull(employees);
this.salaries = requireNonNull(salaries);
}
public DeptEmp deptEmp() { return deptEmp; }
public Employees employees() { return employees; }
public Salaries salaries() { return salaries; }
public static TupleGetter0 deptEmpGetter() {
return DeptEmplEmployeesSalaries::deptEmp;
}
public static TupleGetter1 employeesGetter() {
return DeptEmplEmployeesSalaries::employees;
}
public static TupleGetter2 salariesGetter() {
return DeptEmplEmployeesSalaries::salaries;
}
}
The DeptEmplEmployeesSalaries is simply an immutable holder of the three entities, except it has three additional “getter” methods that can be applied to extract the individual entities. Note that they return TupleGetter, which allows joins and aggregations to use optimized versions compared to just using an anonymous lambda or method reference. Now that we have the custom tuple, we can easily define our Join relation:
private JoinWhen we are building our Join expression, we start off by first using thejoinDeptEmpSal(Departments dept) {
// The JoinComponent is needed when creating joins
JoinComponent jc = speedment.getOrThrow(JoinComponent.class);
return jc.from(DeptEmpManager.IDENTIFIER)
// Only include data from the selected department
.where(DeptEmp.DEPT_NO.equal(dept.getDeptNo()))
// Join in Employees with Employees.EMP_NO equal DeptEmp.EMP_NO
.innerJoinOn(Employees.EMP_NO).equal(DeptEmp.EMP_NO)
// Join Salaries with Salaries.EMP_NO) equal Employees.EMP_NO
.innerJoinOn(Salaries.EMP_NO).equal(Employees.EMP_NO)
// Filter out historic salary data
.where(Salaries.TO_DATE.greaterOrEqual(currentDate))
.build(DeptEmplEmployeesSalaries::new);
}
DeptEmp table (as we recall, this is the many-to-many relation table between Departments and Employees). For this table, we apply a where() statement so that we are able to filter out only those many-to-many relation that belongs to the department we want to appear in the join. Next, we join in the Employees table and specify a join relation where newly joined table’s column
Employees.EMP_NO equal DeptEmp.EMP_NO. After that, we join in the Salaries table and specify another join relation where
Salaries.EMP_NO equal Employees.EMP_NO. For this particular join relation, we also apply a where() statement so that we filter out salaries that are current (and not historic, past salaries for an employee). Finally, we call the
build() method and defines the constructor of our DeptEmplEmployeesSalaries class that holds the three entities DeptEmp, Employees, and Salaries. Counting the Number of Employees for a Department
Armed with the join method above, it is very easy to count the number of Employees for a certain department in the Join stream. This is how we can go about:public long countEmployees(Departments department) {
return joinDeptEmpSal(department)
.stream()
.count();
}
Calculating a Salary Distribution Aggregation
By using the built-in Speedment Aggregator, we can express aggregations quite easily. The Aggregator can consume regular Java Collections, Java Streams from a single table as well as Join Streams without constructing intermediary Java objects on the heap. This is because it stores all its data structures completely off-heap.We first start with creating a “result object” in the form of a simple POJO that is going to be used as a bridge between the completed off-heap aggregation and the Java heap world:
public class GenderIntervalFrequency {
private Employees.Gender gender;
private int interval;
private long frequency;
private void setGender(Employees.Gender gender) { this.gender = gender; }
private void setInterval(int interval) { this.interval = interval; }
private void setFrequency(long frequency) { this.frequency = frequency;}
private Employees.Gender getGender() { return gender; }
private int getInterval() { return interval; }
private long getFrequency() { return frequency; }
}
Now that we have the POJO, we are able to build a method that returns an Aggregation like this: public AggregationThis requires a bit of explanation. When we invoke thefreqAggregation(Departments dept) {
Aggregatoraggregator =
// Provide a constructor for the "result object"
Aggregator.builder(GenderIntervalFrequency::new)
// Create a key on Gender
.firstOn(DeptEmplEmployeesSalaries.employeesGetter())
.andThen(Employees.GENDER)
.key(GenderIntervalFrequency::setGender)
// Create a key on salary divided by 1,000 as an integer
.firstOn(DeptEmplEmployeesSalaries.salariesGetter())
.andThen(Salaries.SALARY.divide(SALARY_BUCKET_SIZE).asInt())
.key(GenderIntervalFrequency::setInterval)
// For each unique set of keys, count the number of entitites
.count(GenderIntervalFrequency::setFrequency)
.build();
return joinDeptEmpSal(dept)
.stream()
.parallel()
.collect(aggregator.createCollector());
}
Aggregator.builder() method, we provide a constructor of the “result object” that we are using as a bridge between the off-heap and the on-heap world. After we have a builder, we can start defining our aggregation and usually the clearest way is to start off with the keys (i.e. groups) that we are going to use in the aggregation. When we are aggregating results for a Join operation, we first need to specify which entity we want to extract our key from. In this case, we want to use the employee’s gender so we invoke
.firstOn(eptEmplEmployeesSalaries.employeesGetter()) which will extract the Employees entity from the tuple. Then we apply .andThen(Employees.GENDER) which, in turn, will extract the gender property from theEmployees entity. The key() method takes a method reference for a method that is going to be called once we want to actually read the result of the aggregation. The second key is specified in much the same way, only here we apply the
.firstOn(DeptEmplEmployeesSalaries.salariesGetter()) method to extract the Salaries entity instead of the Employees entity. When we then apply the .andThen() method we are using an expression to convert the salary so it is divided by 1,000 and seen as an integer. This will create separate income brackets for every thousand dollars in salary. The
count() operator simply says that we want to count the occurrence of each key pair. So, if there are two males that have an income in the 57 bracket (i.e. a salary between 57,000 and 57,999) the count operation will count those two for those keys. Finally, in the line starting with return, the actual computation of the aggregation will take place whereby the application will aggregate all the thousands of salaries in parallel and return an
Aggregation for all the income data in the database. An Aggregation can be thought of as a kind of List with all the keys and values, only that the data is stored off-heap. Adding In-JVM-Memory Acceleration
By just adding two lines to our application, we can get a high-performance application with in-JVM-memory acceleration.Speedment speedment = new EmployeesApplicationBuilder()
.withUsername("...") // Username need to match database
.withPassword("...") // Password need to match database
.withBundle(InMemoryBundle.class) // Add in-JVM-acceleration
.build();
// Load a snapshot of the database into off-heap JVM-memoory
speedment.get(DataStoreComponent.class)
.ifPresent(DataStoreComponent::load);
The
InMemoryBundle allows the entire database to be pulled in to the JVM using off-heap memory and then allows Streams and Joins to be executed directly from RAM instead of using the database. This will improve performance and will make the Java application work more deterministically. Having data off-heap also means that data will not affect Java Garbage Collect allowing huge JVMs to be used with no GC impact. Thanks to the In-memory acceleration, even the biggest department with over 60,000 salaries will be computed in less than 100 ms on my laptop. This will ensure that our UI stays responsive.
Building the UI in Java
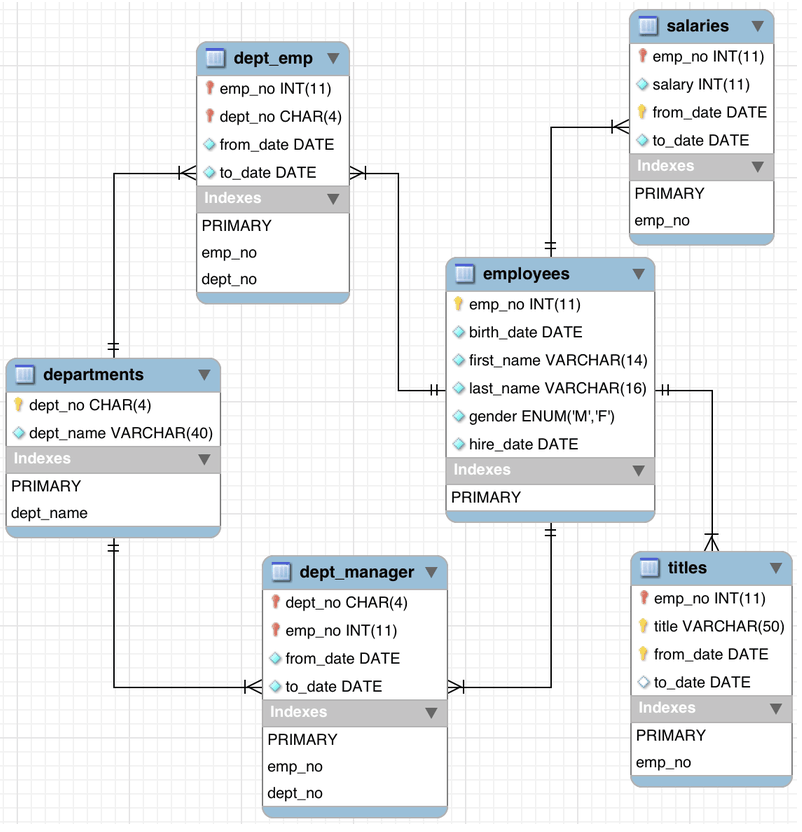
Now that the data model is finished, we move on to the visual aspects of the application. This is as mentioned earlier done utilizing Vaadin, a framework which allows implementation of HTML5 web user interfaces using Java. The Vaadin framework is built on the notion of components, which could be a layout, a button or anything in between. The components are modeled as objects which can be customized and styled in an abundance of ways.The image above describes the structure of the GUI we intend to build for our
DataModel. It constitutes of nine components, out of which five read information from the database and present it to the user while the rest are static. Without further ado, let’s start configuring the UI. 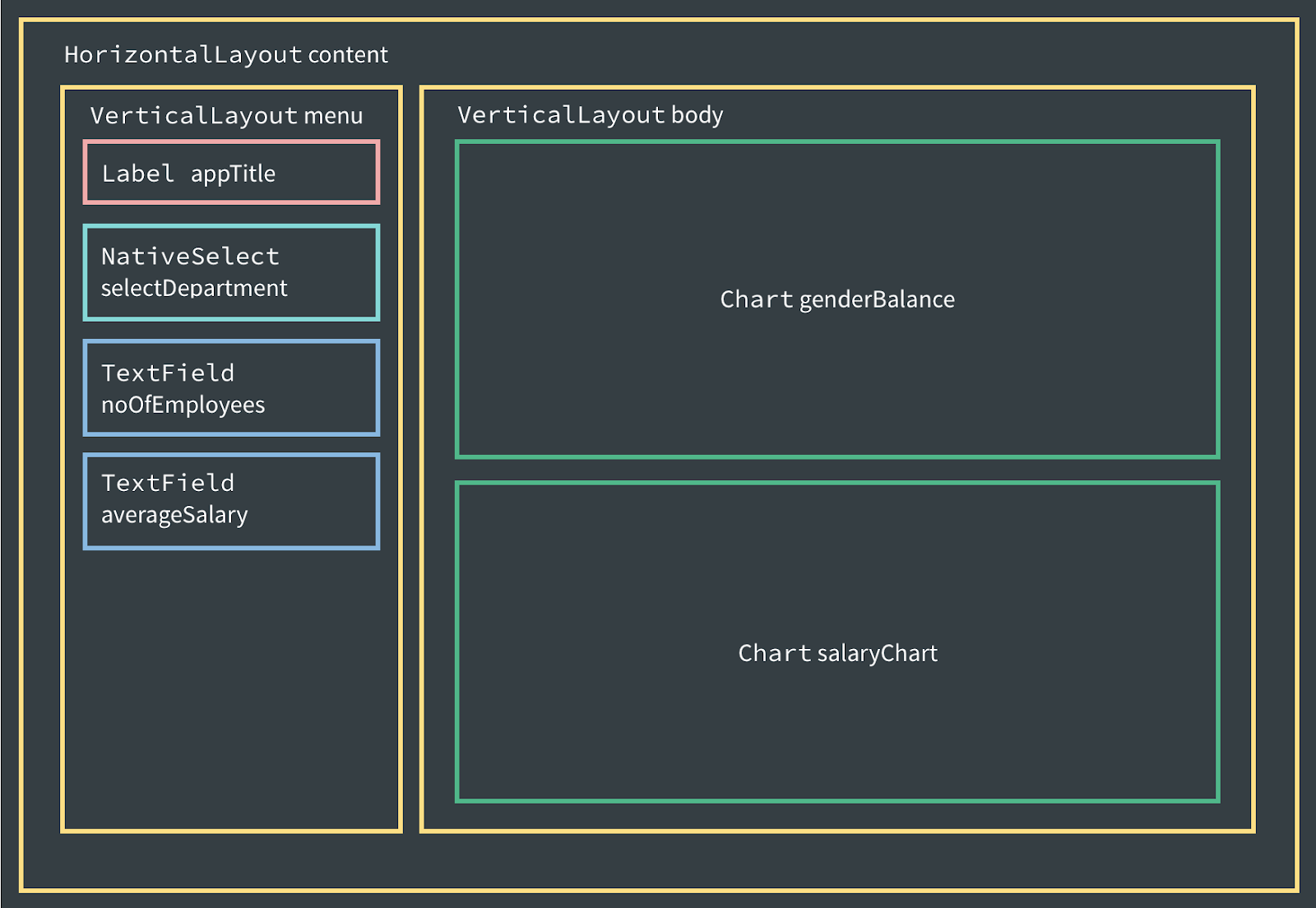 |
A sketch showing the hierarchy of the components included in our GUI. |
The Vaadin UI Layer
To integrate Vaadin in the application, we downloaded a starter pack from Vaadin to set up a simple project base. This will automatically generate a UI class which is the base of any Vaadin application.@Theme("mytheme")
public class EmployeeUI extends UI {
@Override // Called by the server when the application starts
protected void init(VaadinRequest vaadinRequest) { }
// Standard Vaadin servlet which was not modified
@WebServlet(urlPatterns = "/*", name = "MyUIServlet", asyncSupported = true)
@VaadinServletConfiguration(ui = EmployeeUI.class, productionMode = false)
public static class MyUIServlet extends VaadinServlet { }
}
The overridden
init() is called from the server when the application is started, hence this is where we soon will state what actions are to be performed when the application is running. EmployeeUI also contains MyUIServlet, which is a standard servlet class used for deployment. No modification was needed for the sake of this application. Creation of Components
As mentioned above, all of our components will be declared ininit(). This is not suggested as a best practice but works well for an application with a small scope. Although, we would like to collectively update the majority of the components from a separate method when a new department is selected, meaning those will be declared as instance variables along the way. Application Title
We start off simple by creating a Label for the title. Since its value will not change, it can be locallydeclared.
Label appTitle = new Label("Employee Application");
appTitle.setStyleName("h2");
In addition to a value, we give it a style name. Style names allow full control of the appearance of the component. In this case, we use the built-in Vaadin Valo Theme and select a header styling simply by setting the parameter to “h2”. This style name can also be used to target the component with custom CSS (for example .h2 { font-family: ‘Times New Roman; }).
Text Fields
 To view the number of employees and the average salary for the selected department, we use the
To view the number of employees and the average salary for the selected department, we use the TextField component. TextField is mainly used for user text input, although by setting it to read-only, we prohibit any user interaction. Notice how two style name can be used by separating them with a blank space. noOfEmployees = new TextField("Number of employees"); // Instance variable
noOfEmployees.setReadOnly(true);
// Multiple style names are separated with a blank space
noOfEmployees.setStyleName("huge borderless");
This code is duplicated for the
averageSalary TextField although with a different caption and variable name. Charts
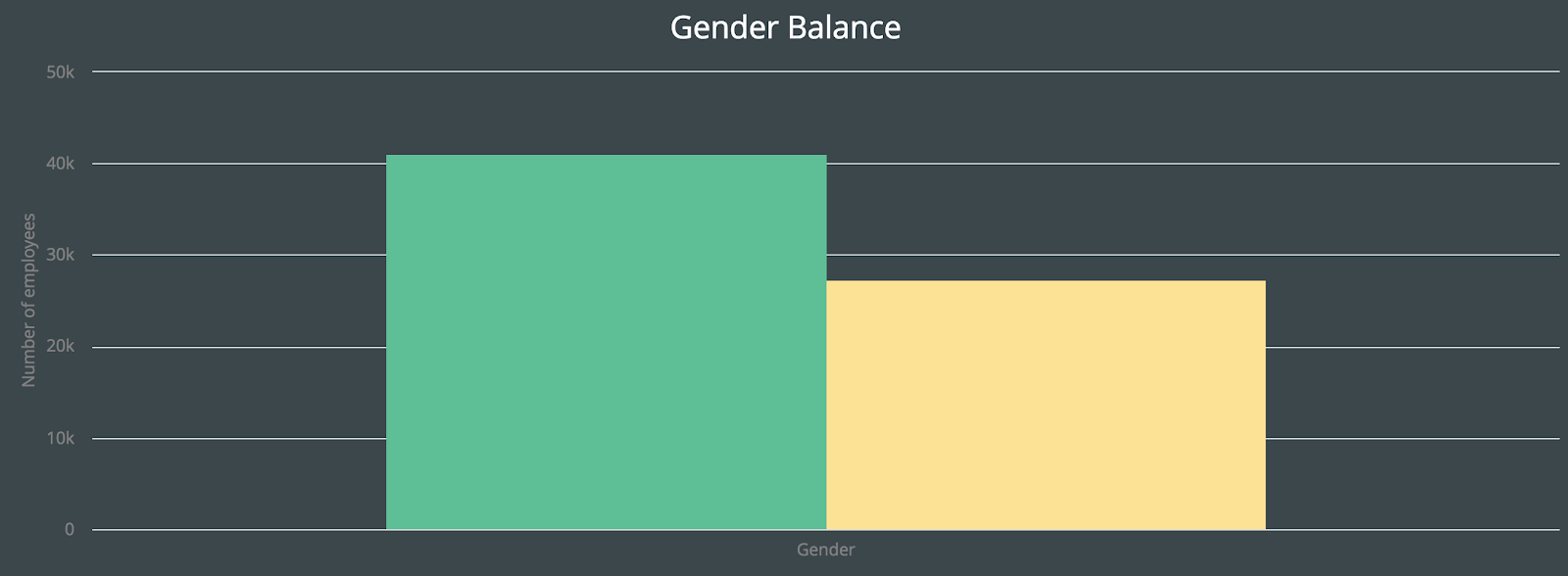 Charts can easily be created with the Vaadin Charts addon, and just like any other component, a chart
Charts can easily be created with the Vaadin Charts addon, and just like any other component, a chart Java Object with corresponding properties. For this application, we used the COLUMN chart to view gender balance and an AREASPLINE for the salary distribution. /* Column chart to view balance between female and male employees at a certain department */Most of the properties associated with a chart are controlled by its configuration which is retrieved with
genderChart = new Chart(ChartType.COLUMN);
Configuration genderChartConfig = genderChart.getConfiguration();
genderChartConfig.setTitle("Gender Balance");
// 0 is only used as an init value, chart is populated with data in updateUI()
maleCount = new ListSeries("Male", 0);
femaleCount = new ListSeries("Female", 0);
genderChartConfig.setSeries(maleCount, femaleCount);
XAxis x1 = new XAxis();
x1.setCategories("Gender");
genderChartConfig.addxAxis(x1);
YAxis y1 = new YAxis();
y1.setTitle("Number of employees");
genderChartConfig.addyAxis(y1);
getConfiguration(). This is then used to add a chart title, two data series, and the axis properties. For the genderChart, a simple ListSeries was used to hold the data because of its simple nature. Although for the salaryChart below, a DataSeries was chosen since it handles a larger and more complicated data sets. The declaration of the
salaryChart is very similar to that of the genderChart. Likewise, the configuration is retrieved and used to add a title and axes. salaryChart = new Chart(ChartType.AREASPLINE);Since both charts display data for male and females we decide to use a shared legend that we fix in the upper right corner of the
salaryChart. /* Legend settings */Lastly, we add two empty
Legend legend = salaryChartConfig.getLegend();
legend.setLayout(LayoutDirection.VERTICAL);
legend.setAlign(HorizontalAlign.RIGHT);
legend.setVerticalAlign(VerticalAlign.TOP);
legend.setX(-50);
legend.setY(50);
legend.setFloating(true);
DataSeries which will be populated with data at a later stage. // Instance variables to allow update from UpdateUI()
maleSalaryData = new DataSeries("Male");
femaleSalaryData = new DataSeries("Female");
salaryChartConfig.setSeries(maleSalaryData, femaleSalaryData);
Department Selector
The final piece is the department selector which controls the rest of the application.
/* Native Select component to enable selection of Department */
NativeSelect<Departments> selectDepartment = new NativeSelect<>("Select department");
selectDepartment.setItems(DataModel.departments());
selectDepartment.setItemCaptionGenerator(Departments::getDeptName);
selectDepartment.setEmptySelectionAllowed(false);
We implement it as a NativeSelect<T> component that calls
departments(), which was previously defined in DataModel, to retrieve a Stream of Departments from the database. Next, we specify what property of Department to display in the dropdown list (default is toString()). Since we do not allow empty selections, we set the
defaultDept to the first element of the Department Stream. Note that the defaultDept is stored as a variable for later use. /* Default department to use when starting application */
final Departments defaultDept = DataModel.departments().findFirst().orElseThrow(NoSuchElementException::new);
selectDepartment.setSelectedItem(defaultDept);
Adding the Components to the UI
So far we have only declared the components without adding them to the actual canvas. To be displayed in the application they all need to be added to the UI. This is usually done by attaching them to aLayout. Layouts are used to create a structured hierarchy and can be nested into one and other. HorizontalLayout contents = new HorizontalLayout();As revealed in the code above, three layouts were used for this purpose, one horizontal and two vertical. Once the layouts are defined we can add the components.
contents.setSizeFull();
VerticalLayout menu = new VerticalLayout();
menu.setWidth(350, Unit.PIXELS);
VerticalLayout body = new VerticalLayout();
body.setSizeFull();
menu.addComponents(appTitle, selectDepartment, noOfEmployees, averageSalary);Components appear in the UI in the order they are added. For a
body.addComponents(genderChart, salaryChart);
contents.addComponent(menu);
// Body fills the area to the right of the menu
contents.addComponentsAndExpand(body);
// Adds contents to the UI
setContent(contents);
VerticalLayout such as the menu, this means from top to bottom. Notice how the HorizontalLayout contents hold the two VerticalLayouts, placing them next to each other. This is necessary because the UI itself can hold only one component, namely contents which holds all components as one unit. Reflecting the DataModel in the UI
Now that all visuals are in place, it is time to let them reflect the database content. This means we need to add values to the components by retrieving information from theDataModel. Bridging between our data model and EmployeeUI will be done by handling events from selectDepartment. This is accomplished by adding a selection listener as follows in init(): selectDepartment.addSelectionListener(e ->Since
updateUI(e.getSelectedItem().orElseThrow())
);
updateUI() was not yet defined, that is our next task. private void updateUI(Departments dept) { }
Here is a quick reminder of what we want updateUI() to accomplish: When a new department is selected we want to calculate and display the total number of employees, the number of males and females, the total average salary and the salary distribution for males and females for that department. Conveniently enough, we designed our
DataModel with this in mind, making it easy to collect the information from the database. We start with the values of the text fields:
final Map<Employees.Gender, Long> counts = DataModel.countEmployees(dept);The sum of the males and females gives the total number of employees.
noOfEmployees.setValue(String.format("%,d", counts.values().stream().mapToLong(l -> l).sum()));
averageSalary.setValue(String.format("$%,d", DataModel.averageSalary(dept).intValue()));
averageSalary() returns a Double which is cast to an int. Both values are formatted as a String before being passed to the text fields. We can also use the Map counts to populate the first graph by retrieving the separate counts for male and female.
final List<DataSeriesItem> maleSalaries = new ArrayList<>();Our
final List<DataSeriesItem> femaleSalaries = new ArrayList<>();
DataModel.freqAggregation(dept)
.streamAndClose()
.forEach(agg -> {
(agg.getGender() == Gender.F ? femaleSalaries : maleSalaries)
.add(new DataSeriesItem(agg.getInterval() * 1_000, agg.getFrequency()));
});
DataModel provides an Aggregation which we can think of as a list containing tuples of a gender, a salary and a corresponding salary frequency (how many persons share that salary). By streaming over the Aggregation we can separate male and female data in two Lists containing DataSeriesItems. A DataSeriesItem is in this case used like a point with an x- and y-value. Comparator<DataSeriesItem> comparator = Comparator.comparingDouble((DataSeriesItem dsi) -> dsi.getX().doubleValue());Before adding the data to the chart, we sort it in rising order of the x-values, otherwise, the graph will look very chaotic. Now our two sorted
maleSalaries.sort(comparator);
femaleSalaries.sort(comparator);
List<DataSeriesItem> will fit perfectly with the DataSeries of salaryChart. //Updates salaryChartSince we are changing the whole data set rather than just a single point, we set the data for our DataSeries to the Lists of x and ys we just created. Unlike a change in a
maleSalaryData.setData(maleSalaries);
femaleSalaryData.setData(femaleSalaries);
salaryChart.drawChart();
ListSeries, this will not trigger an update of the chart, meaning we have to force a manual update with drawChart(). Lastly, we need to fill the components with default values when the application starts. This can now be done by calling
updateUI(defaultDept) at the end of init(). Styling in Java
Vaadin offers complete freedom when it comes to adding a personal feel to components. Since this is a pure Java application only the styling options available in their Java framework were used, although CSS styling will naturally give total control of the visuals. |
A comparison before and after applying the ChartTheme. |
To give our charts a personal touch we created a class
ChartTheme which extends Theme. In the constructor, we defined what properties we would like to change, namely the color of the data series, background, legend, and text. public class ChartTheme extends Theme {
public ChartTheme() {
Color[] colors = new Color[2];
colors[0] = new SolidColor("#5abf95"); // Light green
colors[1] = new SolidColor("#fce390"); // Yellow
setColors(colors);
getChart().setBackgroundColor(new SolidColor("#3C474C"));
getLegend().setBackgroundColor(new SolidColor("#ffffff"));
Style textStyle = new Style();
textStyle.setColor(new SolidColor("#ffffff")); // White text
setTitle(textStyle);
}
}
Then theme was applied to all charts by adding this row to init(): ChartOptions.get().setTheme(new ChartTheme());
Conclusion
We have used Speedment to interface the database and Vaadin to interface the end user. The only code needed in between is just a few Java Streams constructs that declaratively describe the application logic, which grants minimal time to market and cost of maintenance.Feel free to fork this repo from GitHub and start experimenting on your own.
Authors
Julia GustafssonPer Minborg
About
Per Minborg
Per Minborg is a Palo Alto based developer and architect, currently serving as CTO at Speedment, Inc. He is a regular speaker at various conferences e.g. JavaOne, DevNexus, Jdays, JUGs and Meetups. Per has 15+ US patent applications and invention disclosures. He is a JavaOne alumni and co-author of the publication “Modern Java”.