 Often, web applications are slower than we would like them to be. Companies like Google and Facebook have in-house solutions for speeding up their applications. There is a need for a third-party tool that we developers can use to achieve something similar, without needing to spend hours to optimize the code and the database.
Often, web applications are slower than we would like them to be. Companies like Google and Facebook have in-house solutions for speeding up their applications. There is a need for a third-party tool that we developers can use to achieve something similar, without needing to spend hours to optimize the code and the database.The last couple of months, I have been busy contributing to a project that speeds up the response times and also makes it much easier to develop the back end parts of web applications. The project is named Ext Speeder and was developed together with Sencha, the company behind Ext JS. It allows Ext JS developers to speed up their data grids more than 10 times.
Automatically Generated Back End
All back end developers know that there is a lot of work to connect a front end application to the back end. Some of the tasks are to model the database, secure connections, parse http command, deserialize parameters, manage database connections, convert into SQL, optimize queries, parse database response, format into JSON, write XML config, deploy in Java EE and finally verify all the code. Depending on project this may take a couple of days or even several weeksWe have created a tool that connects to an existing database and extracts the schema model so that back end code can be generated automatically. Indeed, there is no need for writing a single line of back end code in most situations. If we have special requirements (like adding our own models to the existing data), it is easy to add or modify the code that was generated by the Ext Speeder tool.
Checkout this 1.5 minute video by a guy that holds the current world-record in developing and deploying a Sencha Ext JS application with the tool (he does it in less than 1.5 minutes). Can it be done faster?
How Much Faster Does it Get?
When an Ext Speeder application is started, it can pull in data we have selected into an in-JVM-memory store so that data can be accessed and processed much faster. Data is also organized in a column oriented way. Thanks to that, sorting and filtering on a column can be done in nanoseconds rather than in seconds. Because Ext Speeder can use an off-heap storage engine, we can pull in an almost unlimited amount of data. An Ext Speeder application can easily handle one hundred million elements. Ext Speeder can also refresh the in-memory data periodically in the background, so that we will see the latest data in the database.Giving fair benchmark figures is always hard. To give an idea, we took an existing public database containing a large number of medical doctors in the US with over 40 million elements and stored them in a standard MySQL server (version 5.6.29) with indexes added to the relevant columns. We then compared typical web access patterns containing sorting, filtering and paging with Ext Speeder versus using the MySQL database directly. On average, Ext Speeder was more than 100 times faster.
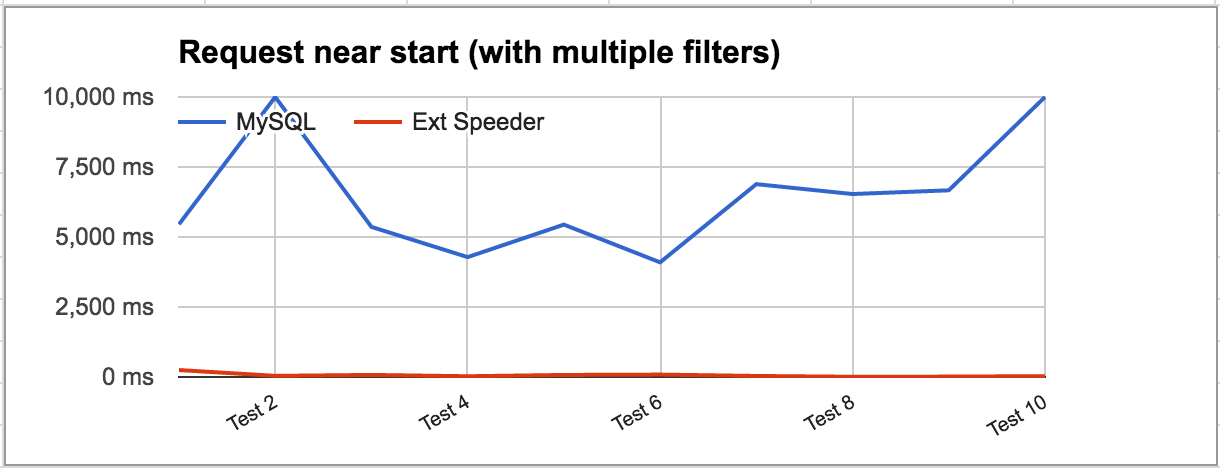
Figure 1, Latency, Ext Speeder vs MySQL standard (less is better) for one of the sub-test
| Property | Value |
|---|---|
| Computer | Lenovio |
CPU | Intel i7-4720HQ CPU @ 2.60GHz |
RAM | 16 GB |
OS | Windows 10 |
Database | MySQL Version 5.6.29 std. install |
Test Tool | Apache JMeter |
What is the real-life gain with such speed improvements, in reality? Well, imagine a web user that is used to waiting some seconds between each interaction. Now that person could suddenly get immediate feed back and the site would feel much more responsive. Check out this 1 minute video to see the difference.
The REST API
Request
The tool is using a standard REST API for querying. If we have a database table named 'doctor', then we can query it like this:http://localhost:4567/MyProject/doctor?
callback=cb&
start=10&
limit=100&
sort=[{"property":"last_name","direction":"ASC"}]&
filter=[{"property":"graduation_year","operator":"lt","value":"1970"}]
This will retrieve doctors that graduated before 1970 sorted by last name starting at the 10:th such doctors and limiting the result to at most 100 physicians. On my laptop, the round trip REST call was completed in less than 0.04 seconds (A human would not notice that kind of delay).
The "sort" attribute can contain several columns so that sorting can be done in many levels.
The 'filter' attribute can be composed of several filters so than several conditions can be applied. We can use the operators Equals ("eq"), Not Equals ("ne"), Less Than ("lt"), Less or Equal ("le"), Greater Than ("gt"), Greater or Equals ("ge") and Contains ("like").
Response
The response to the request above is a JSON string that contains all the matching doctors in the given order. This also makes it very easy to interface with other languages like Java Script, PHP or C#. This is an example of how a response might look like (with limit=2 to reduce size):cb({
"total": 50457,
"data": [
{
"id": 1687657,
"last_name": "AARON",
"first_name": "JOHN",
"suffix": "",
"gender": "M",
"credential": "",
"medical_school_name": "OTHER",
"graduation_year": 1966,
"primary_speciality": "GASTROENTEROLOGY",
"second_speciality": "",
"organization": "ATLANTIC COAST GASTROENTEROLOGY ASSOCIATES",
"organization_dba_name": "",
"street_address_1": "1944 STATE ROUTE 33",
"street_address_2": "",
"supress_street_address_2": "Y",
"city": "NEPTUNE",
"state": "NJ",
"zip_code": "077534863",
"real_zips_ext_id": "RZ-US-07753",
"claims_based_aff_CCN_1": "310038",
"claims_based_aff_LBN_1": "ROBERT WOOD JOHNSON UNIVERSITY HOSPITAL, INC"
},
{
"id": 258680,
"last_name": "ABADEE",
"first_name": "RASHEED",
"suffix": "",
"gender": "F",
"credential": "MD",
"medical_school_name": "OTHER",
"graduation_year": 1968,
"primary_speciality": "PHYSICAL MEDICINE AND REHABILITATION",
"second_speciality": "",
"organization": "",
"organization_dba_name": "",
"street_address_1": "1300 W 7TH ST",
"street_address_2": "SAN PEDRO HOSP",
"supress_street_address_2": "N",
"city": "SAN PEDRO",
"state": "CA",
"zip_code": "90732",
"real_zips_ext_id": "RZ-US-90732",
"claims_based_aff_CCN_1": "050078",
"claims_based_aff_LBN_1": "PROVIDENCE HEALTH SYSTEM - SOUTHERN CALIFORINA"
}
]
});
The 'total' property in the response indicates how many of the rows actually matched the filter (in total) so that data grids can set the appropriate scroll bar location and size.
How Does it Look Like?
This is how an Ext JS data grid application might look like with an Ext Speeder back end:
Deployment
Deployment is easy. Either deploy an Ext Speeder application as a stand-alone application (just run its main Java method) or deploy it as a Java EE application (upload the self-contained WAR file to the server). Any Java EE server would do. For example Tomcat, Glassfish or Oracle WebLogic. This way, the application can automatically benefit from features such as company security policies, authentication, encryption, load balancing etc.Try it for Free!
Go to http://www.extspeeder.com/ to request a free trial. The User's Manual can be found on the same web page. I would be happy to get feedback on the experience or improvement suggestions as a comment on this post.About
Per Minborg
Per Minborg is a Palo Alto based developer and architect, currently serving as CTO at Speedment, Inc. He is a regular speaker at various conferences e.g. JavaOne, DevNexus, Jdays, JUGs and Meetups. Per has 15+ US patent applications and invention disclosures. He is a JavaOne alumni and co-author of the publication “Modern Java”.